

There are so many ways that you can increase website traffic and the number of visitors to your site by using SEO. Some of these techniques work exceptionally well in the Tulsa area. They might seem slow at the start but shall give a long-term benefit. But alternatively, some methods are wrong and unfair to your competitors. These techniques might give you a sudden spurt in traffic but harm the business as visitors might understand the trick that lured them.
There are two new words added to Search Engine Optimization terminology to describe both types of techniques. White Hat Technique is used for correct procedures while Black Hat Technique is used for improper techniques. There is no shortage of methods that fall under both heads. In this article, we shall discuss whether or not White Hat or Black Hat techniques work best in Tulsa.
White Hat Techniques: As discussed earlier, these are techniques which use all the best methods to produce long-term results.
Quality Content: No other thing can help your page more than having good content. This is the one trait that can push everything behind. All the search engines have to retain client loyalty and hence give preference to good content so that they have satisfied clients.
Suitable Titles: Providing correct data titles for the matter on the webpage is essential. This way you can guide readers to the proper place. This parameter works very effectively in getting higher rankings on search engines.
Using Proper Keywords: Knowing what the words are that surfers use to get to your product and using them sporadically on the webpage is helpful in getting good rankings. Keywords provide much-needed direction to surfers and match the pages to their needs.
Black Hat Techniques: They can be called shortcuts to get traffic to your page. Although they might not help in the long term, they can give an immediate push to your site
Using Unrelated Leading Links: By using keywords that are most used by net users on your webpage, you can get a good inflow of clients. Now, if those keywords are not relevant to your product, you can put links on that page and divert clients to your main page. This way you get a good flow on your site even though your product is not related to most searches. Many visitors will read your site and can buy your product. This way might not get you regular buyers but gets you a start.
Copied Content: Many people feel that in this big online world, you can copy from some site and the same will not be tracked. But this is not a good idea as many search engines might ban you from using the same content as another site.
Wrong Advertising: Marketers tend to put their banners on unrelated sites to drive higher traffic. This way, spending increases but does not give good prospects.
With knowledge of all these techniques and their impact, you can design a great webpage and good SEO campaign for promoting your business.
SEO Tips and Tricks for Tulsa
Are you in need of SEO optimization for your firm, but you are not able to choose the perfect firm for your business? With so many SEO firms offering affordable services with a gamut of services, it sometimes becomes very tough to determine the right company which will provide you with affordable services with excellent quality SEO techniques.
Each such SEO firm claims to be the best and offer the most affordable service – in such a case, how do you select a firm which fulfills your business objectives and satisfies all your business needs? We can recommend jsainteractive.com and also give you some tips on how to hire an SEO marketing firm for your business:
Search online – If you are looking for an SEO marketing firm, you shouldn’t search anywhere beyond the online stores. This is the place where you will get the best of SEO firms and companies which shall help your business to prosper and you to make huge profits.
SEO companies will undoubtedly have their online presence where you can get an idea of their whole range of services along with their pricing. You can quickly go through their services offered, check various packages, choose your package either by deciding yourself or taking professional help from such companies. Searching online is recommended since you will be able to check out the profiles of several companies, compare their pricing and features and decide for yourself.
SEO optimization services – You will find many companies offering massive ranges of services to their customers, but you need to remember that you might not need all such services. Hence, when you choose any SEO marketing firm for your business remembers to browse through their SEO optimization services. Some common SEO optimization includes directory submissions, article submission, link building, press release submissions, and similar kind of services.
Many firms offer specialized services to their customers which include video submission and Video SEO techniques. You can get your website analysis done to find out the kind of SEO optimization you need for your business and based on such reports, and you can hire the services. This is suggested, or else you will end up wasting your money and time.
SEO Pricing In Tulsa – This is one of the few things which needs immediate consideration and is quite essential to making your choice for which SEO firm to hire. You shouldn’t ignore pricing strategies of different firms. Before you start an online search for an SEO marketing firm, carry out small market research to find out about the SEO pricing of similar firms in Tulsa.
Find out the way the pricing has been set. Pricing is generally in packages or as per individual services hired. If you hire an SEO marketing firm, you need to ensure that you have understood the pricing structure of the firm well and it is on par with the similar firms in the locality. In case you find that the pricing is slightly different, you need to try and find out the reason for such a difference so that you are sure that you are not being cheated.
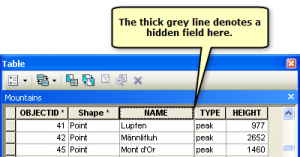 As you can see, this level contains two forms. The upper one is the Send password to Sam button, and the lower one is the password field. You should already have noticed the highly suspicious hidden field in the upper form. Its purpose is obvious: it supplies the email address that the password will be emailed to. From merely knowing this address, you cannot achieve anything (except if you managed to hack the hulla-balloo.com server). Therefore, you should alter the field to contain your email address instead of Sams.
As you can see, this level contains two forms. The upper one is the Send password to Sam button, and the lower one is the password field. You should already have noticed the highly suspicious hidden field in the upper form. Its purpose is obvious: it supplies the email address that the password will be emailed to. From merely knowing this address, you cannot achieve anything (except if you managed to hack the hulla-balloo.com server). Therefore, you should alter the field to contain your email address instead of Sams. This will remove the edit-permissions from users who have not yet logged in. If a guest tries to edit, they will be prompted to log in. Since you would no longer be able to edit using only your IP address as a signature, adding the following line might be desired too:
This will remove the edit-permissions from users who have not yet logged in. If a guest tries to edit, they will be prompted to log in. Since you would no longer be able to edit using only your IP address as a signature, adding the following line might be desired too: Trying to access the page was fruitless, and so was trying to access
Trying to access the page was fruitless, and so was trying to access  A while ago, I posted about using FireStats for MediaWiki statistics. For some weeks now, Ive been using FireStats for tracking statistics on this WordPress blog, too. This is by far the best statistics plugin that I have ever seen. You can find out most things about your visitors patterns through a nice AJAX interface. Also, it doesnt use any JavaScript against visitors, which wins it a lot of points in my eyes.
A while ago, I posted about using FireStats for MediaWiki statistics. For some weeks now, Ive been using FireStats for tracking statistics on this WordPress blog, too. This is by far the best statistics plugin that I have ever seen. You can find out most things about your visitors patterns through a nice AJAX interface. Also, it doesnt use any JavaScript against visitors, which wins it a lot of points in my eyes. Download and Install
Download and Install Todo
Todo This is how to do it on your TI calculator, nicely formated.
This is how to do it on your TI calculator, nicely formated.